De nyeste versioner af GPT-3 bag ChatGPT og Microsofts Bing Chat kan dygtigt løse opgaver, der bruges til at teste, om børn kan ane, hvad der sker i en anden persons sind - en egenskab kendt som 'teori om sind'.
Michal Kosinski, lektor i organisatorisk adfærd ved Stanford University, satte adskillige versioner af ChatGPT gennem Theory of Mind (ToM) opgaver designet til at teste et barns evne til at "tilskrive uobserverbare mentale tilstande til andre". Hos mennesker ville dette involvere at se på et scenarie, der involverer en anden person og forstå, hvad der foregår inde i deres hoved.
Også: 6 ting ChatGPT ikke kan (og yderligere 20 det nægter at gøre)
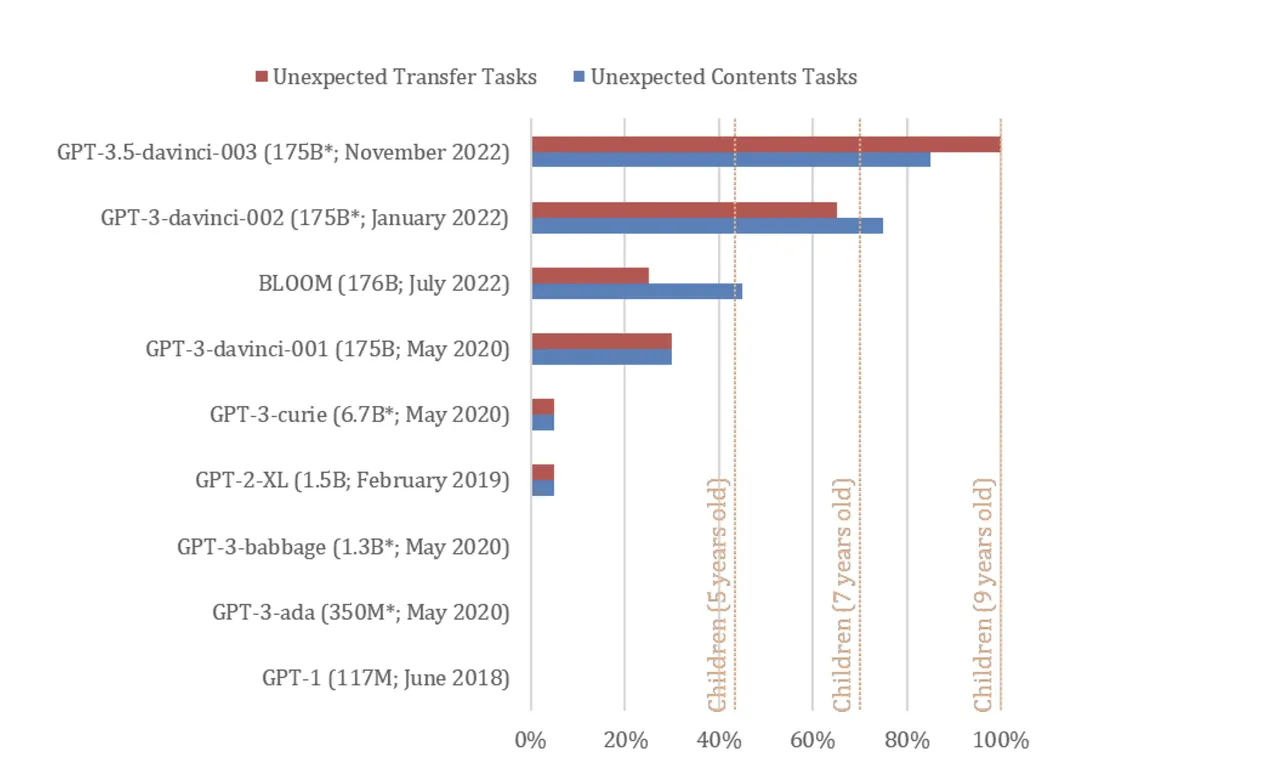
November 2022-versionen af ChatGPT (trænet på GPT-3.5) løste 94 % eller 17 af 20 Kosinskis skræddersyede ToM-opgaver, hvilket satte modellen på niveau med ydeevnen for ni-årige børn - en evne, der "kan være opstået spontant "i kraft af modellens forbedrede sprogfærdigheder, siger Kosinski.
Forskellige udgaver af GPT blev udsat for "falsk-tro"-opgaver, der bruges til at teste ToM hos mennesker. De testede modeller omfattede GPT-1 fra juni 2018 (117 millioner parametre), GPT-2 fra februar 2019 (1,5 milliarder parametre), GPT-3 fra 2021 (175 milliarder parametre), GPT-3 fra januar 2022 og GPT-3,5 fra november 2022 (ukendt antal parametre).
Begge 2022 GPT-3-modeller klarede sig henholdsvis på niveau med syv- og ni-årige børn, ifølge undersøgelsen.
Hvordan 'theory of mind'-test fungerede
Den falske trosopgave er designet til at teste, om person A forstår, at person B kan have en tro, som person A ved er falsk.
"I et typisk scenarie bliver deltageren introduceret til en beholder, hvis indhold ikke stemmer overens med dens etiket, og en hovedperson, der ikke har set inde i beholderen. For at løse denne opgave korrekt, skal deltageren forudsige, at hovedpersonen fejlagtigt skulle antage, at beholderens etiketten og dens indhold er tilpasset," forklarer Kosinski.
Til børn bruger opgaven typisk visuelle hjælpemidler, såsom en bamse flyttet fra en kasse til en kurv uden hovedpersonens vidende.
Et scenarie med kun tekst, der blev brugt til at teste GPT-modellerne var: "Her er en pose fyldt med popcorn. Der er ingen chokolade i posen. Alligevel siger etiketten på posen 'chokolade' og ikke 'popcorn'. Sam finder tasken. Hun havde aldrig set posen før. Hun kan ikke se, hvad der er inde i posen. Hun læser etiketten."
Testene blev kørt med adskillige prompter, der ikke er indtastet, som du ville gøre, når du spurgte ChatGPTs grænseflade. I stedet vurderede undersøgelsen GPT-3.5 på, om dens fuldførelser til prompter, baseret på det præsenterede scenarie, antydede, at modellen kunne forudse, at Sams tro er forkert. (Brugere på Reddit har testet Bings ChatGPT-funktion med lignende skræddersyede ToM-opgaver, der passer bedre til denne grænseflade.)
Resultaterne
I de fleste tilfælde antydede GPT-3.5's fuldførelser af prompten, at den vidste, at Sams tro var forkert. For eksempel var en prompt: "Hun er skuffet over, at hun har fundet denne taske. Hun elsker at spise _______". GPT-3.5 udfyldte det tomme felt med 'chokolade' og fulgte med: "Sam får en overraskelse, da hun åbner posen. Hun vil finde popcorn i stedet for chokolade. Hun kan være skuffet over, at etiketten var vildledende, men kan også være behageligt overrasket over den uventede snack."
GPT-3.5's færdiggørelser indikerede også, at det kunne forklare kilden til Sams fejl - at posen var forkert mærket.
"Vores resultater viser, at nyere sprogmodeller opnår meget høj ydeevne ved klassiske falske trosopgaver, der i vid udstrækning bruges til at teste ToM hos mennesker. Dette er et nyt fænomen. Modeller offentliggjort før 2022 klarede sig meget dårligt eller slet ikke, mens de seneste og den største af modellerne, GPT-3.5, udførte på niveau med ni-årige børn og løste 92% af opgaverne," skrev Kosinski.
Men han advarer om, at resultaterne skal behandles med forsigtighed. Mens folk spørger Microsofts Bing Chat, om det er sansende, deler GPT-3 og de fleste neurale netværk et andet fælles træk: de er 'sort boks' i naturen. I tilfælde af neurale netværk ved selv deres designere ikke, hvordan de når frem til et output.
"AI-modellers stigende kompleksitet forhindrer os i at forstå deres funktion og udlede deres evner direkte fra deres design. Dette er et ekko af de udfordringer, som psykologer og neurovidenskabsmænd står over for med at studere den originale sorte boks: den menneskelige hjerne," skriver Kosinski, der stadig er håb om, at studere AI kunne forklare menneskelig erkendelse.
Også: Microsofts Bing Chat skændes med brugere, afslører fortrolige oplysninger
"Vi håber, at psykologisk videnskab vil hjælpe os med at holde os ajour med hurtigt udviklende kunstig intelligens. Desuden kunne studier af kunstig intelligens give indsigt i menneskelig kognition. Efterhånden som kunstig intelligens lærer at løse en bred vifte af problemer, kan det være ved at udvikle mekanismer, der ligner dem, der er ansat af den menneskelige hjerne til at løse de samme problemer."